


Site Reliability Engineering (SRE) has emerged as a critical discipline for ensuring the reliability and scalability of complex systems. As companies strive to deliver uninterrupted services, the role of SREs becomes indispensable in bridging the gap between development and operations. This comprehensive guide delves deep into the principles, practices, and tools that define site reliability engineering, offering valuable insights for organizations aiming to enhance their system reliability and performance.
Understanding Site Reliability Engineering

Site Reliability Engineering is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. The creation of highly dependable and scalable software systems is the primary objective. The term was coined at Google in 2003 when a team was tasked with making Google’s already large-scale sites more reliable, efficient, and scalable.
Core Principles of Site Reliability Engineering
Service Level Objectives (SLOs): Define and measure what constitutes acceptable performance and reliability for a service. SLOs are critical in setting realistic expectations and understanding the thresholds that dictate when to engage in operational work.
Error Budgets: These are directly tied to SLOs and define the acceptable amount of unreliability. Error budgets provide a metric to balance innovation and reliability, ensuring that teams can deploy new features without compromising service stability.
Monitoring and Observability: Implement comprehensive monitoring systems to gain insights into the system’s health and performance. Observability extends beyond monitoring by enabling engineers to understand and explore how the system behaves under various conditions.
Automation: Automate repetitive tasks to reduce human error and increase efficiency. Automation spans deployment processes, scaling operations, and incident responses, allowing SREs to focus on more strategic activities.
Continuous Integration and Continuous Deployment (CI/CD)
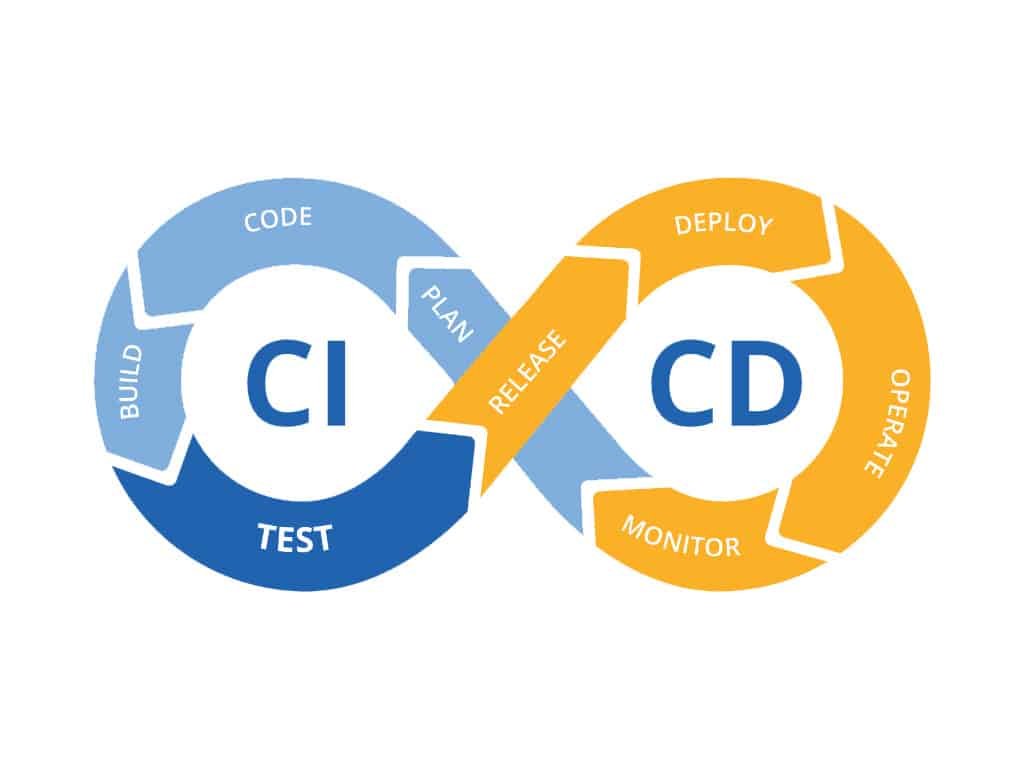
Implementing CI/CD pipelines is crucial for maintaining the reliability of applications. CI/CD automates the integration and deployment processes, ensuring that changes are tested and deployed seamlessly, reducing the risk of errors and downtime.
Site Reliability Engineering Chaos Engineering
Chaos engineering involves deliberately injecting failures into the system to test its resilience. By simulating real-world outages and disruptions, teams can identify weaknesses and improve the system’s ability to withstand unexpected issues.
Site Reliability Engineering Capacity Planning and Scaling
Effective capacity planning ensures that systems can handle varying loads without degradation in performance. This involves forecasting demand, planning for growth, and implementing strategies to scale horizontally or vertically as needed.
Blameless Postmortems
After an incident, conducting blameless postmortems helps teams analyze what went wrong without assigning blame. This practice encourages transparency, learning, and continuous improvement, fostering a culture of trust and collaboration.
Tools and Technologies for Site Reliability Engineering
Monitoring and Alerting Tools
Prometheus: An open-source monitoring solution that collects metrics, stores them, and allows for powerful queries and visualizations.
Grafana: Often used with Prometheus, Grafana provides a rich visualization platform for monitoring data, enabling detailed dashboards and alerts.
Datadog: A monitoring and security platform that provides comprehensive insights into infrastructure and application performance.
Automation Tools
Terraform: An effective and safe tool for creating, modifying, and versioning infrastructure. It uses declarative configuration files to manage the infrastructure lifecycle.
Ansible: A task automation, application deployment, and configuration management tool that is available as open-source software.
Jenkins: A popular CI/CD tool that automates the parts of software development related to building, testing, and deploying, facilitating continuous integration and continuous delivery.
Incident Management Tools for Site Reliability Engineering
PagerDuty: An incident management platform that helps teams detect and resolve incidents quickly, minimizing downtime.
Opsgenie: A tool for incident response orchestration and on-call management, ensuring that the right people are alerted at the right time.
VictorOps: A platform designed for DevOps and IT teams to manage incident response and on-call schedules effectively.
The Role of Site Reliability Engineers
Site Reliability Engineers (SREs) are pivotal in maintaining the balance between releasing new features and ensuring system stability. Their responsibilities include:
Designing Reliable Systems: SREs work closely with development teams to design systems that are inherently reliable and resilient.
Implementing Automation: By automating routine tasks, SREs reduce manual intervention and focus on higher-value activities.
Managing Incidents: SREs lead incident response efforts, ensuring quick resolution and learning from incidents to prevent future occurrences.
Performance Tuning: They continuously monitor and optimize system performance to meet SLOs and user expectations.
Building a Culture of Reliability
A strong culture of reliability is essential for successful SRE implementation. This involves:
Encouraging Collaboration: Fostering close collaboration between development and operations teams to ensure shared responsibility for system reliability.
Prioritizing Reliability: Integrating reliability into the software development lifecycle, making it a key consideration from the outset.
Learning from Failures: Promoting a culture where failures are seen as learning opportunities and continuous improvement is encouraged.
Challenges in Site Reliability Engineering
While the benefits of SRE are substantial, organizations may face challenges such as:
Cultural Resistance: Shifting to an SRE model requires a cultural change that some teams might resist.
Skill Gaps: Finding and training engineers with the necessary skills to excel in an SRE role can be difficult.
Complexity: Managing the complexity of large-scale systems requires sophisticated tools and practices, which can be daunting to implement and maintain.
Future of Site Reliability Engineering
The future of SRE looks promising as more organizations recognize the importance of reliability in delivering superior user experiences. Key trends include:
Increased Automation: Advancements in AI and machine learning will drive further automation in incident response and system management.
Enhanced Observability: Improved observability tools will provide deeper insights into system behavior, facilitating proactive management.
Broader Adoption: As the benefits become more apparent, a wider range of industries beyond tech will adopt SRE principles and practices.
Conclusion
Site Reliability Engineering is a transformative approach that ensures systems are reliable, scalable, and efficient. By embracing the core principles and practices of SRE, organizations can achieve a higher level of service reliability and operational excellence. From setting clear SLOs to automating processes and fostering a culture of continuous improvement, the journey to reliable systems is both challenging and rewarding.
Read more: Google AI Chatbot



